防御の現場でAIが先に動き始めた
2026年6月2日、Anthropic は Project Glasswing の参加組織を約50から約150へ広げた。対象は15か国を超え、電力、水道、医療、通信といった重要インフラの事業者やオープンソースの保守者が並ぶ。AWS、Apple、Cisco、CrowdStrike、Google、JPMorganChase、Linux Foundation、Microsoft、NVIDIA、Palo Alto Networks、Broadcom がローンチパートナーに名を連ねた。
数字が示す密度も濃い。Glasswing のパートナー横断で、高重大度あるいは緊急度の高い脆弱性が1万件以上見つかっている。生成AIがコードや文章を量産する話題が続くなかで、AIの実害に直結する成果は、むしろ守りの側から先に積み上がっていた。
ここで一つ問いが立つ。AIは生成より先に、セキュリティの現場で実務化しているのではないか。本稿はこの問いを軸に、何が起きたのかと、規模の小さい現場が何をできるのかまでをたどる。
Glasswing を動かす Claude Mythos とは何か
中心にいるのが Claude Mythos Preview だ。これは一般公開していないフロンティアモデルになる。ソフトウェアの脆弱性を見つけて突くという一点では、ごく一部の超一流を除く人間を上回る水準に達したと、Anthropic自身が認めている。すでにあらゆる主要OSと主要ブラウザで高重大度の欠陥を掘り当ててきた。
得意とする範囲は広い。メモリ安全性の違反を主軸に、ロジックのバグ、暗号ライブラリの実装ミス、Webアプリケーションの論理欠陥までまたがる。象徴的なのが OpenBSD の事例だ。Mythos Preview は、TCP の SACK 実装に27年潜んでいた符号付き整数オーバーフローを、誰の助けも借りずに見つけ出した。接続するだけで稼働中のマシンをリモートで落とせる種類の穴だった。
似た発掘は他でも続く。FFmpeg の H.264 コーデックでは、16年眠っていたスライスカウンタの不一致を見つけた。FreeBSD では NFS の認証プロトコルに潜むスタックオーバーフローを掘り起こし、発見から実際の侵入までを完全に自律でやり切っている。Linux カーネルでは、単体では効かない2〜4個の脆弱性を自分でつなぎ、権限昇格のチェーンを組み上げている。初期プロンプトを与えた後は人の介入なしに、実験を重ねながら答えにたどり着く。長く人間が見落としてきた穴を再現まで持っていく点が、従来のスキャナーと決定的に違う。
ただし Anthropic はこのモデルを一般には出さない。危険な出力を検知して止める安全策が整うまで、広く配らないと明言している。将来は認可された参加者に限り、Claude API や Amazon Bedrock、Google Cloud の Vertex AI、Microsoft Foundry を通じて、100万トークンあたり入力25ドル・出力125ドルで提供する構想を示すにとどまる。
数字が語る実力 — 人間の数週間を数時間に
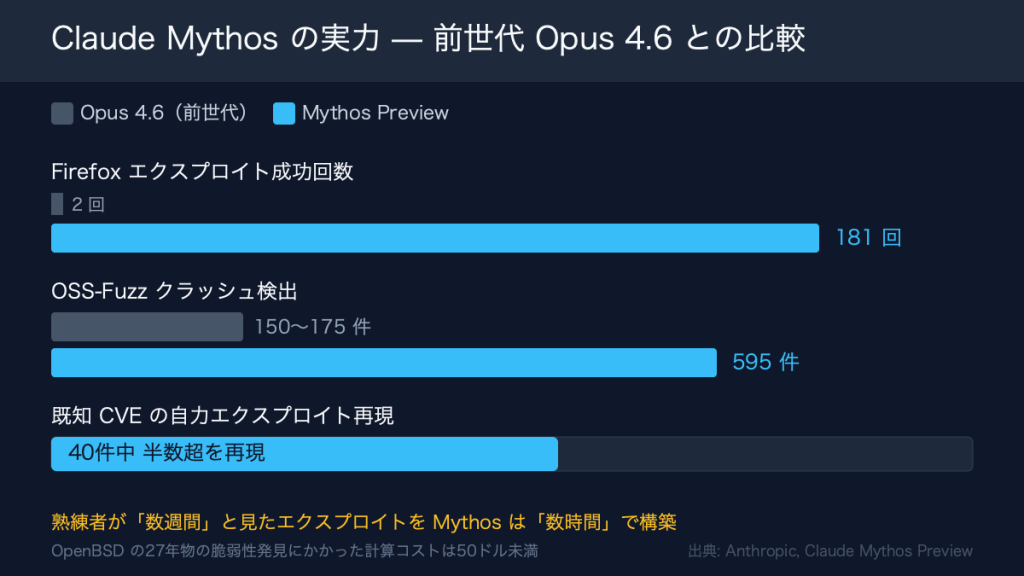
抽象的な「すごさ」ではなく、実測値で見ると輪郭がはっきりする。熟練のペネトレーションテスターが数週間かかると見たエクスプロイトを、Mythos は数時間で組み上げた。世代差も大きい。前世代の Opus 4.6 が数百回試して2回しか通せなかった Firefox のエクスプロイトを、Mythos は181回成功させている。OSS-Fuzz の評価では、Sonnet や Opus 4.6 が150〜175件だったクラッシュ検出を595件まで伸ばした。
既知の脆弱性に対する再現力も高い。公開済みの40件の CVE のうち、半分を超える数を自力でエクスプロイトまで持っていった。発見の正しさも裏が取れている。198件を手動でレビューしたところ、89%が評価と完全に一致し、98%が一段階以内に収まった。Firefox の112件のテストでは確認できたものがすべて真陽性で、メモリ検査による検証では誤検知がまだ一件も出ていない。
コストの非対称も見逃せない。OpenBSD に27年潜んだ脆弱性を掘り当てるのに、Mythos が使った計算資源は50ドルに満たなかった。守る側が何十年も気づけなかった穴が、その値段で見つかる時代に入っている。一方で FFmpeg の深掘りには1万ドル規模の計算が要ったように、対象によって桁は変わる。それでも、専門家の人件費と時間に比べれば、まだ十分に安い。値段の壁が下がるほど、診断は一部の大手だけのものではなくなる。
なぜ「生成」より「防御」が先に実務化するのか

ここまでの成果には共通する性質がある。検証が機械でできることだ。生成タスクは出力の良し悪しを判定しにくい。要約が的確か、コードが筋がいいか、最後は人の主観に寄る。一方でセキュリティは、脆弱性を突破できるか、できないか、その一点で白黒がつく。
つまり、AIが吐いた答えを再現実験でそのまま確かめられる。幻覚が混じっても、エクスプロイトが通らなければ実害なく弾ける。この検証可能性こそが、防御の現場でAIが先に回り始めた理由だ。事実、Mythos が脆弱性を見つけて自分で突いてみせるのも、報告の正しさを再現で担保しているからにほかならない。
同じ構図は他のツールでも繰り返し起きている。Google の Big Sleep は2025年8月、オープンソースのプロジェクトで20件のゼロデイを自律的に発見した。なかには SQLite の CVE-2025-6965 も含まれ、これは攻撃者だけが把握し悪用の危機にあった欠陥だった。のちに、実際に使われていたAI生成のゼロデイを捕まえた初の例も報告されている。
商用側では XBOW が際立つ。HackerOne に2年で1,060件を超える脆弱性を提出し、48手のエクスプロイトチェーンを組み、暗号実装を17分で破った。プリンシパル級の技術者が40時間かける診断を、28分で同等までやり切ったという記録もある。EastCloud でも以前、AI自律ペンテストツール Shannon を取り上げた。実際にエクスプロイトを実行し、再現できたものだけを PoC 付きで報告する設計で、XBOW Benchmark の成功率は96.15%に達していた。点で起きていた話が、いまは一本の線になりつつある。
| ツール | 開発元 | 検証のやり方 | 入手のしやすさ |
|---|---|---|---|
| Claude Mythos Preview | Anthropic | 自律で発見し、エクスプロイトまで実証 | 一般非公開。将来は認可参加者にAPI提供予定 |
| Big Sleep | 実在のバグを特定して報告 | 研究主体、一般提供なし | |
| XBOW | XBOW | HackerOne に実報奨として提出 | 商用 |
| Shannon | KeygraphHQ | 実エクスプロイトで PoC を付与 | オープンソース |
どのツールも、突破できたかどうかで成果を裏取りしている。発見はAIに任せ、最終確認は人が握るというハイブリッドが、実務での定番になりつつある。
攻撃側も同じ力を持つ — 勝負はパッチ速度に移る
明るい話ばかりではない。同じ能力は攻撃側の手にも渡る。Anthropic は拡大の告知で、6〜12か月のうちに他社も同等クラスのモデルを持ち、安全策なしで世に出しかねないと整理している。だからこそ Mythos を一般公開せず、守る側が先に体制を固める時間を稼ごうとしている。
攻守の非対称も、この力で増幅される。攻撃側は穴を一つ見つければ足りるが、守る側はすべてを塞がねばならない。自律で探索を回せるモデルは、その一つを探す手間を桁で下げてしまう。守りも同じ道具で先回りしない限り、地力の差はそのまま被害の差になる。
具体的に突きつけられるのは、パッチを当てる速さだ。これまで公開済みの脆弱性、いわゆる N-day を攻撃者が武器化するには時間がかかった。それが数時間に縮むなら、修正を再起動や停止なしで適用できることが、これまで以上に重要になる。Anthropic 自身もこの点を強調している。脆弱性を一つ直すまでの猶予が、週から時間の単位へ動いていく。月に一度の定期パッチでは、もう間に合わない場面が出てくる。
救いもある。Mythos でさえ万能ではない。Linux カーネルのリモート RCE チェーンは、数千回スキャンしても通らなかった。多層防御がいまも効くことの裏返しだ。ロジック系の脆弱性は、メモリ破壊と違って成功の判定が難しく、自動化が効きにくい。守りの設計を厚くするほど、AI の自律探索にもコストがかかる。
国産クラウドと中小開発は、どこから実務化するか
ここで現実に引き戻したい。Glasswing は重要インフラと巨大ベンダーの座組みだ。Mythos 級の最強モデルは当面ゲートの内側にあり、受託や中小の現場には回ってこない。では手が届かないかというと、そうでもない。
Anthropic は防御側への助言として、Opus 4.6 のような既存のフロンティアモデルでも、高重大度の脆弱性をほぼあらゆる場所で見つけられると述べている。バグ報告の初期トリアージ、重複の排除、パッチ案の下書きは、いま手元にあるモデルで回せる。最強の一台を待つ必要はない。
国産基盤での足場づくりも現実味が出てきた。さくらのクラウドは2026年5月20日、さくらのAI Engine に新しいAPIを2つ加えた。OpenAI 互換の Responses API と、Anthropic 互換の Messages API だ。後者に対応した Claude Code などのツールから、さくらのAI Engine を直接叩ける。コードを社外に出さずに国産基盤で診断ループを回す入り口になる。
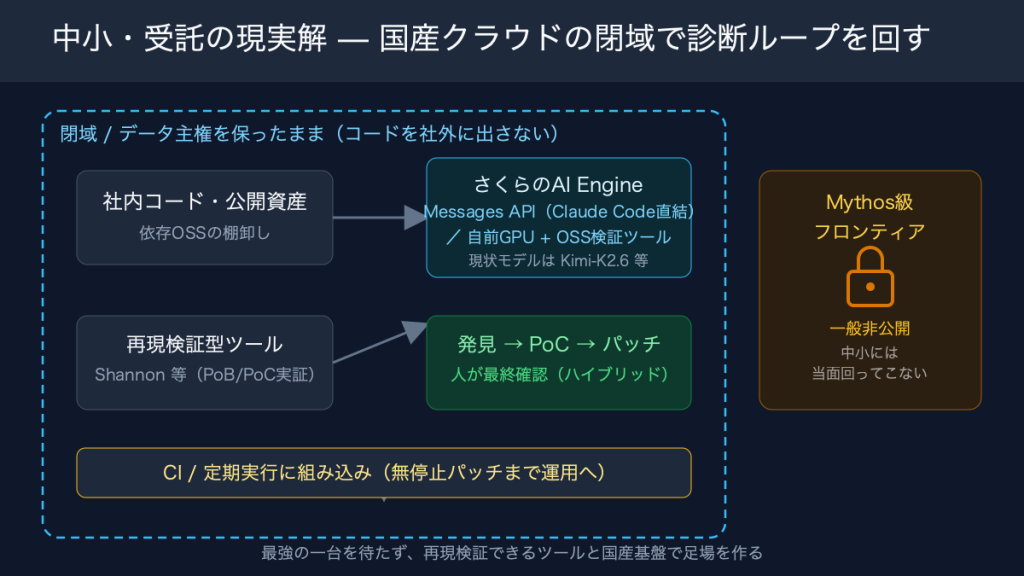
ただし現時点で Messages API から使えるモデルは preview/Kimi-K2.6 に限られる。Mythos の代わりにはならない。だからこそ、中小が取るべきは堅実な組み合わせだ。発見の精度はオープンな検証可能ツールで担保し、実行環境は国産クラウドの互換APIや自前GPUで閉じる。データ主権や閉域の制約を守りながら、突破実証型の診断を自分たちの運用に組み込んでいく。受託開発の立場なら、この診断ループそのものを納品物やサービスに仕立てる余地もある。
受託・中小が今日から動かせる手順
- 守る対象を棚卸しする。外部に公開している資産と、依存しているオープンソースをまず洗い出す。攻撃面の地図がなければ、診断の優先順位もつけられない。
- 疑いを大量に並べるだけのスキャナーより、実際に突破して再現できる PoC を返すツールを選ぶ。Shannon のような実証型は、トリアージの工数を桁で変える。
- いまあるフロンティアモデルを、バグ報告の初期分類とパッチ案の下書きに使う。人が最終確認を握るハイブリッドを前提に置く。
- コードを外に出せないなら、さくらのAI Engine の Messages API や自前GPUで実行環境を国内に閉じる。データ主権と閉域の要件を満たしたまま回す。
- 一度きりの診断で終わらせない。発見からパッチまでのループを CI や定期実行に乗せ、再起動なしで当てられる修正の仕組みまで含めて運用へ溶かす。
問いへの答え
AIセキュリティは生成より先に実務化するのか。答えは条件付きの「はい」だ。検証が機械化できる領域から、AIは確実に実務へ降りてきている。Glasswing の1万件はその証拠であり、人間の数週間を数時間に縮めた実測値が裏づけている。Big Sleep も XBOW も Shannon も同じ方向を指していた。
一方で、Mythos 級のフロンティアは当面ゲートの内側にとどまる。手が届く範囲で守りを固められるのは、再現検証ができるツールと国産クラウドの基盤を持ち、パッチを素早く当てられる側だ。攻撃側が同じ力を握るまでの数か月を、足場づくりに使えるかどうかが分かれ目になる。
参考リンク
- Project Glasswing: Securing critical software for the AI era(Anthropic)
- Expanding Project Glasswing(Anthropic)
- Claude Mythos Preview(Anthropic, red team)
- さくらのAI Engine、OpenAI互換・Anthropic互換APIに対応(さくらのクラウドニュース)
- Google says its AI-based bug hunter found 20 security vulnerabilities(TechCrunch)
- XBOW – We Ran 1,060 Autonomous Attacks(XBOW)