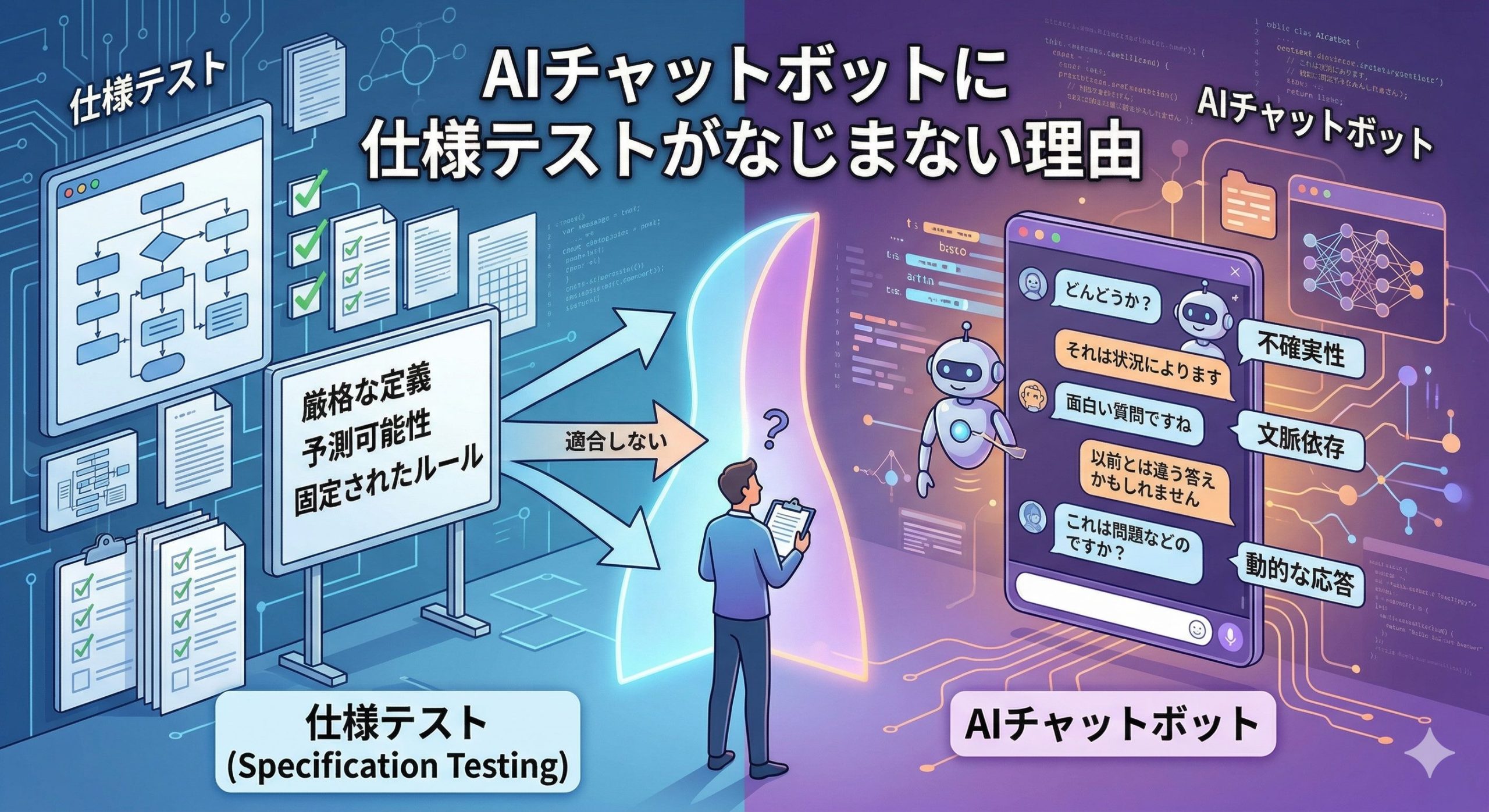
はじめに
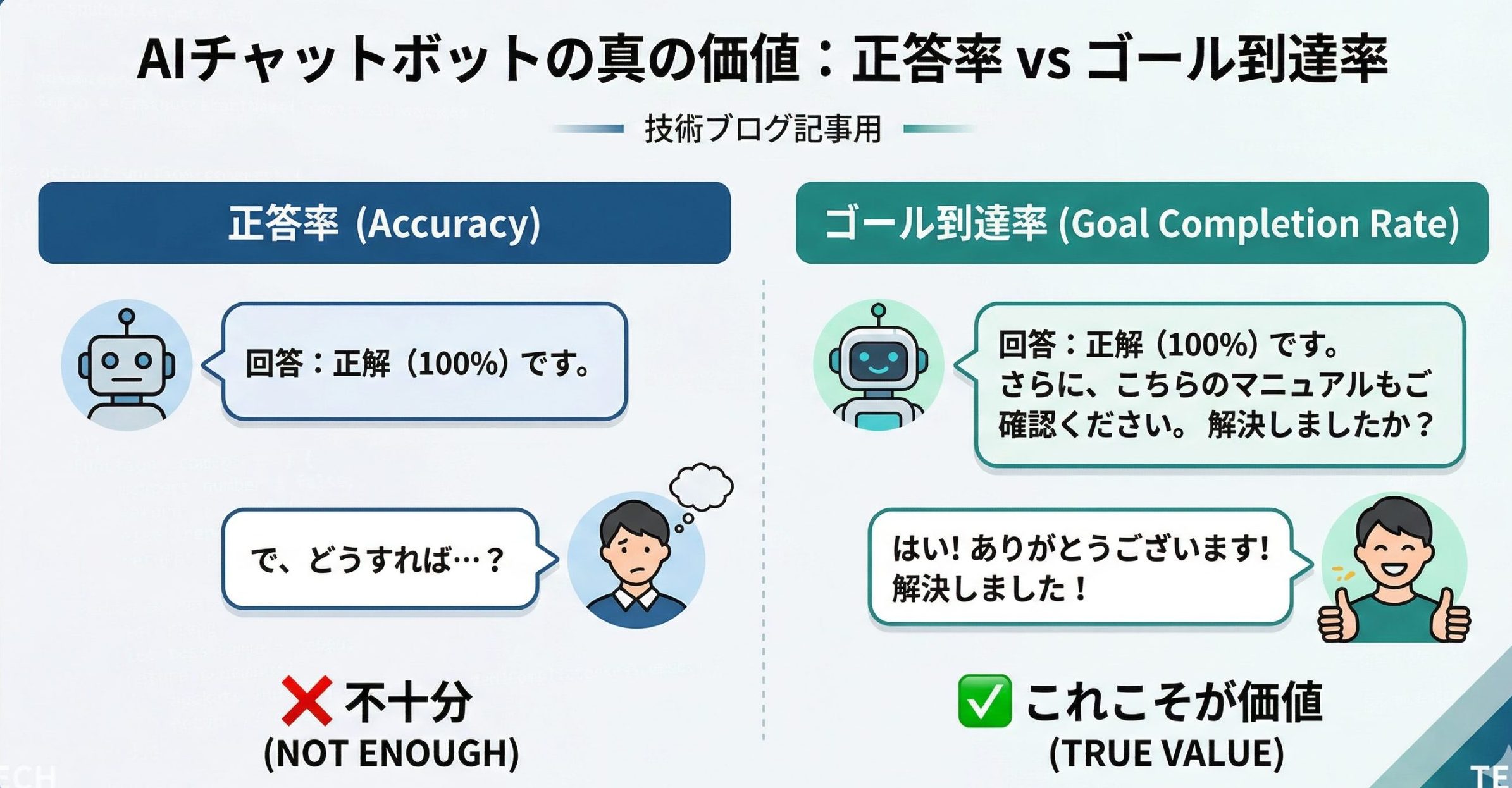
AIチャットボットを評価するとき、技術者ほど見たくなるのが正答率である。どれだけ正しい答えを返せたか、期待した回答とどれだけ一致したか、という見方である。
この考え方はわかりやすい。数字にも落としやすく、従来の検索精度や分類精度の延長で捉えやすいからである。ただし、AIチャットボットを実務で運用するうえでは、正答率だけを見ても価値は測りにくい。
なぜなら、AIチャットボットの役割は、正しい文章を返すことそのものではなく、利用者を目的地へ近づけることにあるからである。実際の現場では、少し言い換えれば伝わる場面もあれば、最初の回答が完璧でなくても問い返しを通じてゴールへ到達できる場面も多い。
本記事では、AIチャットボットの価値を正答率ではなくゴール到達率で見るべき理由を整理し、実務でどのように評価軸を置くべきかをまとめる。
先に結論
- AIチャットボットの価値は、1回の返答の正しさだけでは決まらない
- 重要なのは、会話全体として利用者が目的へ近づけたかどうかである
- 正答率は参考指標にはなるが、中心指標にはなりにくい
- 実務では、ゴール到達率のほうが利用価値に近い
- 評価軸を変えると、設計・テスト・改善の観点も変わる
なぜ正答率で見たくなるのか
正答率は、技術者にとって最も扱いやすい指標の1つである。入力があり、期待値があり、一致したら正解、不一致なら不正解という形にしやすいからである。
たとえば、次のような評価は非常にやりやすい。
- FAQに対して正しい答えを返したか
- 定義されたラベルに正しく分類したか
- 期待した定型文に近い返答をしたか
この評価は、単発の応答やルールベースに近い処理では有効である。だが、AIチャットボットでは、会話の役割がそれだけでは終わらない。利用者の意図整理、問い返し、論点分解、次の行動提示まで含むため、1回の返答の正しさだけでは価値を測れない。
正答率が高くても、価値が低いことはある
実務では、正答率が高く見えても使われないAIチャットボットがある。典型的なのは、質問に対しては正しい情報を返すが、利用者が次にどう動けばよいかまではつながらないケースである。
たとえば、社内ヘルプデスクで「ログインできない」と聞かれたときに、一般的な原因一覧を正しく返したとしても、利用者にとって必要なのが「今この状況で何を確認すればよいか」であれば、その回答は十分とは言えない。
転職相談のような会話でも同様である。「転職活動は自己分析が大事です」と正しいことを返しても、利用者が知りたいのが「今の悩みをどう整理すればよいか」であれば、正答ではあっても会話の価値は低い。
正答率は高くても、利用者が前に進めなければ価値は低い。AIチャットボット評価の難しさはここにある。
少し外していても、価値が高いことはある
逆に、最初の返答が模範回答と少し違っていても、結果として利用者をゴールへ近づけられるなら、その会話は価値がある。
たとえば、利用者が曖昧な相談をしてきたとき、いきなり正しい結論を返せなくても、問い返しで状況を整理し、論点を絞り、必要な行動を示せるなら、その会話は十分に機能している。
AIチャットボットが「答えを返す仕組み」ではなく「会話を進める仕組み」だからこそ、評価も1回の返答の正解率より、最終的な到達状態で見るほうが実態に合う。
ゴール到達率とは何か
ここでいうゴール到達率とは、利用者が会話を通じて、本来目指していた状態へ近づけた割合を指す。重要なのは、回答文そのものではなく、会話の結果として利用者がどうなったかである。
ゴールの例は、用途によって異なる。
- 社内ヘルプデスクなら、次の確認手順が明確になっている
- 申請案内なら、必要な申請ルートがわかっている
- 転職相談なら、悩みの種類が整理されている
- 面接対策なら、回答の下書きができている
このように、AIチャットボットの価値は返答文の正しさだけではなく、会話後の利用者状態で判断したほうが妥当である。
正答率中心で運用すると何が起きるのか
AIチャットボットを正答率中心で評価すると、設計も改善もその方向へ寄る。すると、次のような問題が起きやすい。
- 問い返しを減らして定型回答へ寄せる
- 想定外の会話を避けるようになる
- 文面が少し違う返答を不正解にする
- 利用者の状況より、期待回答との一致を優先する
- 実運用では使いにくいのに、評価上は高得点になる
正答率を最上位に置くと、AIチャットボットを従来の固定応答システムへ戻してしまいやすい。結果として、AIの強みである柔軟な整理や想定外対応が削られる。
ゴール到達率で見ると、評価軸が変わる
ゴール到達率を中心に置くと、見るべき観点は次のように変わる。
- 利用者の意図を捉えられたか
- 必要な問い返しができたか
- 論点を整理できたか
- 次の行動へつなげられたか
- 会話全体として目的へ近づけたか
この見方にすると、1回の返答ごとの細かい文面一致よりも、会話の前進度が重要になる。改善の方向も変わり、単なる表現修正ではなく、問い返しの質、ゴール設計、戻し方の設計へ目が向くようになる。
具体例1:社内ヘルプデスク
社内ヘルプデスク型のチャットボットで考えるとわかりやすい。利用者が「VPNにつながらない」と相談したとする。
このとき、正答率中心なら「VPN接続トラブルの一般回答を出せたか」を見がちである。だが、実際に価値があるのは、次のどちらかである。
- 利用者自身で一次切り分けできるようになった
- 適切な窓口へ正しくエスカレーションできた
価値は一般論を返したことではなく、会話後に利用者が適切に動けるようになったかで決まる。この場合、ゴール到達率のほうが実態に近い。
具体例2:転職相談チャットボット
転職相談チャットボットでも同じである。利用者が「転職したいけど何から始めるべきかわからない」と相談したとする。
このとき、正答率中心なら「転職準備の一般的な手順を返したか」を見やすい。だが、利用者によって必要なものは異なる。
- そもそも転職すべきかを整理したい人
- 退職理由をまとめたい人
- 職務経歴書の整理から始めるべき人
重要なのは、一般的な正答を返すことではなく、その人の今の状態に合った次の一手を示せることである。評価も「正しいことを言ったか」ではなく、「その人が次に進めたか」で見るべきになる。
正答率が使える場面もある
ここで注意したいのは、正答率がまったく不要というわけではないことである。AIチャットボットでも、正答率が向く場面はある。
正答率が向く領域
- FAQの定型回答
- ルールに基づく単純な案内
- 分類タスクや抽出タスク
- 禁止回答のチェック
正答率だけでは足りない領域
- 曖昧な相談の整理
- 問い返しが必要な会話
- 複数論点が混ざる会話
- 次の行動提案が重要な会話
正答率は部分指標としては有効だが、会話システム全体の価値指標にはなりにくい。用途ごとに使い分ける必要がある。
AIと自動化の境界
このテーマでも、AIと自動化の境界を分けて考えると整理しやすい。
AIに任せる範囲
- 利用者の意図理解
- 問い返し
- 論点整理
- 次の一手の提案
ルール・自動化で処理する範囲
- 禁止事項の制御
- 定型フローへの接続
- エスカレーション条件の判定
- 外部システム連携の形式保証
人が判断する範囲
- 高リスクな最終判断
- 例外対応の承認
- 評価指標の見直し
- 会話品質の改善判断
この切り分けがあると、どこを正答率で見て、どこをゴール到達率で見るべきかが見えやすくなる。
期待値の明示
できること
- 利用者を目的地へ近づける
- 曖昧な相談を整理する
- 次の行動を提示する
できないこと
- すべての会話を1回の返答で完結させること
- 正答率だけで利用価値を表すこと
- 高リスク判断を完全自動化すること
苦手な条件
- ゴールが未定義のまま評価する場合
- 会話を単発QAとしてしか見ない場合
- 正答率を唯一の指標にしてしまう場合
運用で事故りやすいポイント
- 誤判定パターン:文面が正しければ価値があると見なしてしまう
- データ品質依存で崩れる例:評価用の正解データが単発QAしか想定していない
- 監視・ログ:会話ごとの到達状態、問い返し率、途中離脱率は見たい
- レビュー/承認フロー:到達できなかった会話を人が定期レビューする
- 例外時の対応:ループ、誤誘導、高リスク会話は人へ戻す条件を明示する
よくある落とし穴
- 症状:正答率は高いのに使われない
- 原因:利用者の到達状態を見ていない
- 回避策:会話後に何ができるようになったかで評価する
- 症状:会話が定型文ばかりになる
- 原因:正答率を上げるために自由度を削っている
- 回避策:一部は正答率で管理しつつ、会話品質は別指標で見る
- 症状:改善しても利用満足が上がらない
- 原因:表現ばかり直して、ゴール設計を見直していない
- 回避策:会話の着地点と前進度を改善対象にする
判断に迷ったときの指針
- 正答率で見る条件:定型回答やルール判定など、正解が固定しやすい部分
- ゴール到達率で見る条件:曖昧な相談整理や次の一手の提示など、会話の価値が重要な部分
- 最終的な推奨:部分品質は正答率で管理し、全体価値はゴール到達率で見る
まとめ
AIチャットボットの価値は、単に正しい文章を返せるかでは決まらない。重要なのは、会話全体として利用者を目的地へ近づけられたかどうかである。
正答率は便利な指標だが、それだけでは実運用の価値を取りこぼしやすい。特に、問い返しや論点整理が重要な会話では、ゴール到達率のほうが本質に近い。AIチャットボットを評価するときは、1回の返答の正しさだけでなく、会話後の利用者状態まで含めて見る必要がある。
関連キーワード
- メインキーワード:AIチャットボット 正答率
- 同義語:AIチャットボット ゴール到達率、AIチャットボット 評価指標
- 関連領域:AIチャットボット 品質評価、AIチャットボット 会話設計、AIチャットボット テスト