
はじめに
AIエージェントを本番運用しようとすると、インフラ側の課題が意外と多くあります。サーバーの管理、コンテナのデプロイ、シークレットの扱い、監視……。アプリケーションの開発に集中したいのに、インフラ運用に時間を取られる構造になりやすいです。
今回はそこを解消するために、さくらのクラウドのマネージドサービスを組み合わせて、できる限り運用負荷をゼロに近づけたAIエージェント実行基盤を構築しました。本記事ではその構成と設計の考え方を紹介します。
全体構成
構成の概要は以下の通りです。
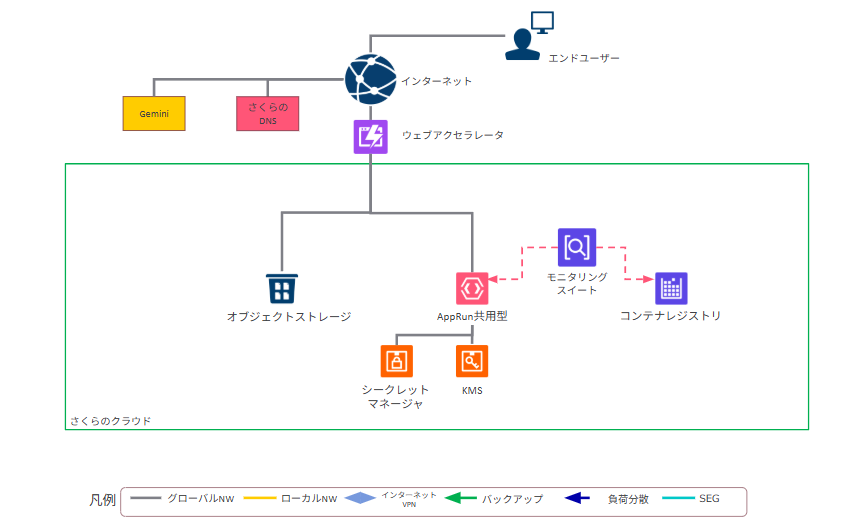
エンドユーザー
↓
インターネット
↓(さくらのDNS / Gemini)
ウェブアクセラレータ(Cloudflare Turnstile)
↓
[さくらのクラウド]
├── オブジェクトストレージ(静的サイト/フロントエンド)
└── AppRun(共用型/バックエンド) ← モニタリングスイートで監視
↓
シークレットマネージャ / KMS
コンテナレジストリフロントエンドはオブジェクトストレージ上に静的サイトとしてデプロイしており、バックエンドはAppRunで動かしています。エンドユーザーからのリクエストはさくらのDNSとウェブアクセラレータを経由してさくらのクラウド内に入ります。さくらのクラウド内はすべてマネージドサービスで構成されており、自前でサーバーを管理する箇所はありません。
各コンポーネントの役割
オブジェクトストレージ(フロントエンド)
フロントエンドはオブジェクトストレージ上に静的サイトとしてデプロイしています。S3互換APIに対応しているため、既存のデプロイフローをほぼ変更せずに利用できます。サーバーを持たずに静的サイトをホスティングできるため、フロントエンドの運用負荷はほぼゼロです。
AppRun(共用型/バックエンド)
AIエージェントのバックエンド処理を担うコンテナ実行環境です。フロントエンドからのリクエストを受け取り、AI APIを呼び出して結果を返します。サーバーレスに近い感覚で使えるため、スケーリングやサーバー管理から解放されます。
Cloudflare Turnstile
AIエージェントの実行基盤では、Botによる不正リクエストがAI APIトークンの浪費や意図しない負荷につながるリスクがあります。今回はCloudflare Turnstileをフロントエンド・バックエンドの両方に導入し、二重でBot排除を行っています。
- フロントエンドURL(オブジェクトストレージの静的サイト):アクセス時点でTurnstileによる検証を行い、Botからのアクセスをブロックします。
- バックエンドURL(AppRun):APIリクエストを受け付ける際にも再度検証し、フロントエンドを迂回した直接アクセスも排除します。
この二重検証により、AI APIの不正利用やトークンの浪費を防ぐ構成になっています。
シークレットマネージャ / KMS
AppRunからAI API(OpenAI、Geminiなど)を呼び出す際のAPIトークンをシークレットマネージャで管理し、KMSで暗号化しています。ソースコードや環境変数にトークンをハードコードするリスクを排除し、APIトークンの管理方法を標準化できます。
コンテナレジストリ
AppRunで動かすコンテナイメージを管理します。CI/CDパイプラインからイメージをプッシュし、AppRunがそこからプルする構成にすることで、デプロイフローをシンプルに保てます。
モニタリングスイート
AppRunの動作状況を監視しています。稼働状態やエラーをリアルタイムで把握できます。マネージドサービスのため、監視基盤そのものの管理コストもかかりません。
ウェブアクセラレータ
CDN機能を担います。静的アセットのキャッシュによる高速化だけでなく、さくらのクラウド内への入口を一本化する役割も果たしています。
設計のポイント:なぜフルマネージドにこだわったか
AIエージェントは本質的にステートレスな処理が多く、コンテナ実行環境と相性が良いです。一方で、APIトークンや外部サービスとの連携が増えるため、セキュリティ面の管理コストが高くなりやすいです。
フルマネージド構成にした主な理由は2つです。
1. 運用負荷の削減
サーバーのOSアップデート、ミドルウェアの管理、スケーリング設定——これらをすべてマネージドサービスに委ねることで、アプリケーションの開発・改善に集中できます。
2. セキュリティの標準化
シークレットマネージャとKMSを使うことで、APIトークンの管理方法が標準化されます。個々の開発者が独自の方法でトークンを扱うリスクを減らせます。
さくらのクラウドを選んだ理由
外資クラウドと比較したとき、さくらのクラウドには国産ならではの強みがあります。データが国内に留まること、円建てでの料金体系、そして日本語サポートです。公共性の高いシステムや、データ主権を重視するプロジェクトでは特に有効な選択肢になります。
今回の構成で使用したAppRun、オブジェクトストレージ、コンテナレジストリ、シークレットマネージャ、KMS、モニタリングスイートはいずれもさくらのクラウドのマネージドサービスとして提供されており、一つのプラットフォーム内で完結できた点もメリットでした。
まとめ
さくらのクラウドのマネージドサービスを組み合わせることで、AIエージェントの実行基盤をフルマネージドで構築できました。フロントエンドはオブジェクトストレージで静的ホスティング、バックエンドはAppRunでコンテナ実行、Cloudflare Turnstileで二重のBot排除——それぞれをマネージドサービスで賄うことで、サーバー管理から完全に解放された構成になっています。
さくらのクラウドでのAIエージェント基盤構築を検討している方の参考になれば幸いです。
よくある質問
Q. さくらのクラウドのAppRunとAWSのECSやCloud Runとの違いは?
AppRunは国内データセンターで完結するため、データ主権を重視する案件に適しています。またAWSやGCPと異なり円建て料金のため、為替リスクなく安定したコスト管理ができます。
Q. フルマネージド構成にするとコストは上がりますか?
初期の利用料は上がる場合がありますが、インフラ管理の人件費や障害対応コストを含めたトータルコストでは削減できるケースが多いです。
Q. AIエージェントのAPIトークンはどのように管理していますか?
シークレットマネージャとKMSで暗号化して管理し、ソースコードや環境変数には一切持たせていません。またCloudflare Turnstileでフロントエンド・バックエンド双方への不正アクセスも防いでいます。
Q. さくらのクラウドだけで本番運用に耐えられますか?
今回の構成ではAppRun・モニタリングスイート・ウェブアクセラレータを組み合わせることで、可用性・監視・CDNをすべてカバーしています。

