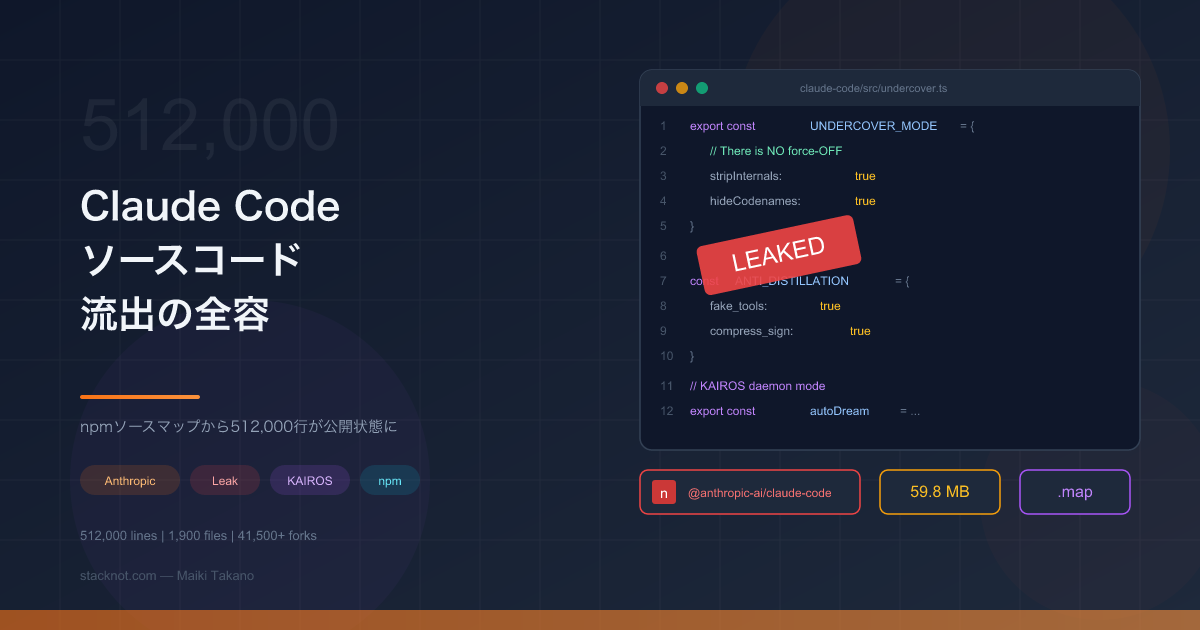
2026年3月31日、AnthropicのAI開発支援CLI Claude Codeのソースコードがnpmレジストリから流出した。約512,000行、1,900ファイルのTypeScriptがソースマップ経由で丸見えになっていた。
騒ぎが大きくなった理由はタイミングにもある。わずか5日前の3月26日、Anthropicは未発表モデル Claude Mythos(内部コードネーム Capybara)のブログ下書きをCMSの設定ミスで公開していた。そのとき漏れた約3,000アセットにはベンチマーク情報まで含まれていた。5日間で2度目の漏洩。リリースプロセスそのものの信頼性が問われている。
何が起きたのか — 59.8MBのソースマップが混入
セキュリティ研究者 Chaofan Shou氏(@Fried_rice )が、npm上の @anthropic-ai/claude-code v2.1.88に59.8MBのソースマップファイル .map が含まれているのを見つけた。
ソースマップは、ビルド済みのJavaScriptから元のTypeScriptソースを復元するためのデバッグ用ファイルだ。開発環境でしか使わないはずのもので、公開パッケージに入れてはいけない。それがそのまま混入していた。
直接原因は.npmignoreの設定漏れ
Claude CodeのビルドにはBunのバンドラーが使われている。直接の原因と背景は別の話だ。
直接原因 はリリース担当者が.npmignoreに*.mapを追記し忘れたこと。package.jsonのfilesフィールドでの除外もされていなかった。Anthropicは公式声明でリリースパッケージングのヒューマンエラーと認め、顧客データや認証情報は含まれていないとしている。
一方、背景因子 としてBunのIssue #28001がある。2026年3月11日に報告されたもので、development: falseを設定してもBun.serveがソースマップへの参照を出力に残すバグだ。Bunはデフォルトでソースマップを生成するため、明示的に除外しないとパッケージに入ってしまう。
しかもこれは初めてではない。2025年にもClaude Code v0.2.8とv0.2.28で同様のソースマップ混入が起き、npmレジストリから該当バージョンを削除していた。同じミスの繰り返しだ。
DMCAは効かなかった — 一度広まったコードは消えない
流出コードはGitHub上に即座にバックアップされ、ピーク時には41,500以上のフォーク がついた。AnthropicはDMCA通知を出し、8,100以上のリポジトリが削除対象になった。
だが拡散の速度に削除が追いつかなかった。DMCA削除からわずか2時間後にはPythonリライトやRustリライトが出回り、後者は47,000スターを集めている。別言語で書き直すことでDMCAの著作権主張を回避する手法だ。一度広まったコードは消せない。
流出コードから判明した5つの内部設計
512,000行のTypeScriptから、Claude Codeの設計思想が見えてきた。
1. 約40のプラグイン型ツールアーキテクチャ
Claude Codeはファイル読み込み、Bash実行、Web取得、LSP連携といった機能をそれぞれ独立したツールとして実装している。ツール定義だけで29,000行。すべてにパーミッションゲートがかかっている。
これらを束ねるクエリエンジンが46,000行。ターミナルUIはReact + Inkで描画し、文字幅計算にはInt32ArrayバッキングのASCIIキャッシュを使って通常の約50倍に高速化している。ゲームエンジンで使われる手法をCLIに転用している。
2. セッションを超えた記憶 — メモリシステム
memdir/ というメモリディレクトリが、セッション間のコンテキスト保持を担っている。関連する記憶のスキャン、古い記憶のエージング、チーム間での共有。Claude Codeがコードベースを覚えているように感じるのは、この仕組みのおかげだ。
3. トークンコストを抑えるキャッシュ最適化
14個のキャッシュ破棄ベクトルを追跡し、APIコールごとのトークン消費を減らしている。システムプロンプトの変更箇所だけを差分で送るキャッシュ境界管理で、同じプロンプトの再送信を避けている。
4. マルチエージェント調整
coordinatorMode.tsがエージェント間のオーケストレーションを受け持つ。プロンプトベースで調整し、「弱い成果物を無批判に承認するな」といった品質管理の指示が埋め込まれている。サブエージェントが並列で動くときの競合回避とマージの制御もここで行う。
5. 23個のセキュリティ検査を持つBashツール
Bashツールには23個の検査が組み込まれている。18個のZsh組み込みコマンド制限、ゼロ幅文字のインジェクション防御など。プロンプトインジェクション経由でシステムコマンドが実行されるのを多層で防いでいる。
未公開機能の発見 — Anthropicの次の一手が見えた
コードにはまだリリースされていない機能フラグが複数あった。
KAIROS — 常時稼働する自律デーモンモード
古代ギリシャ語で「最適なタイミング」を意味するKAIROS。いまのClaude Codeはユーザーの入力を受けてから動くリアクティブなツールだが、KAIROSはバックグラウンドで常時走るデーモンになる。
autoDream — ユーザーがアイドル中に、散らばった観測結果を統合し矛盾を除去する「メモリ蒸留」プロセス。/dreamスキルとして実装されている追記専用ログ — 日次で観測・判断・アクションを記録し、判断根拠をトレースできるようにするGitHubウェブフック購読 — リポジトリのイベントを監視し、PRレビューやIssue対応を自律的にこなす5分間隔のcronスケジュール — 定期的に<tick>プロンプトを受け取り、能動的に動くかどうかを判断するBriefモード — 常駐アシスタントがターミナルを埋めないよう、極端に短い応答だけ返す出力モード
実現すれば、コマンドを打って結果を待つ開発スタイルから、AIがバックグラウンドでコードベースを監視し続けるスタイルへ移行する。GitHub CopilotのAgent ModeやCursorのBackground Agentと方向は同じだが、デーモン化はさらに一歩踏み込んでいる。
Undercover Mode — AI生成を隠すステルス貢献
undercover.tsは約90行。外部リポジトリでClaude Codeの痕跡を消すモードだ。有効にすると、以下が適用される。
Claude Code、Capybara、Tenguなどの内部コードネームを一切出さない
内部Slackチャンネル名やリポジトリ名を出力しない
AI生成の痕跡を残さない
Anthropic社員がオープンソースにClaude Codeで貢献するとき、AIが書いたと分からないようにする仕組みだ。
この機能にはオフのスイッチがない 。コード内のコメントに「There is NO force-OFF」と書かれている。CLAUDE_CODE_UNDERCOVER=1で強制オンはできるが、逆はできない。一方通行の設計になっている。
AI生成コードの透明性が問われている時期に、AIであることを隠す機能があること自体が論争を呼んでいる。EUのAI Actが求める透明性要件、GitHubのContributor Covenantとの整合性はどうなるのか。そして皮肉なことに、情報漏洩を防ぐためのこのモードが含まれたコード自体が漏れた。
Anti-Distillation — 競合のモデル蒸留を防ぐ2段構え
モデル蒸留とは、Claudeの応答を別のモデルの学習データとして転用する行為だ。コードにはこれを防ぐ2系統の仕掛けがあった。
第1層 。claude.tsのフラグANTI_DISTILLATION_CCが有効だと、APIリクエストにanti_distillation: ['fake_tools']が付く。サーバー側がこれを受けて偽のツール定義をシステムプロンプトに注入する。競合がトラフィックを記録して学習に使っても、偽ツールの混入で精度が落ちる。GrowthBookのフィーチャーフラグ tengu_anti_distill_fake_tool_injection で制御されている。
第2層 。betas.tsのサーバーサイドコネクタがアシスタントの応答テキストを圧縮・署名して返す。傍受しても元の応答を正確に復元できない。
ネイティブクライアント証明 — DRMライクな正規バイナリ検証
system.tsで、リクエストのx-anthropic-billing-headerにcch=00000というプレースホルダーが埋め込まれている。送信直前にBunのネイティブ層、Zig実装のHTTPスタックが計算ハッシュに置き換える。公式バイナリからのリクエストかどうかをサーバーが検証するDRMに近い仕組みだ。
この技術はオープンソースクローン OpenCode との争いにも絡んでいる。Anthropicは流出の約10日前、3月21日前後に、サブスクリプション料金での内部API不正利用を理由にOpenCodeへ法的脅迫状を送っていた。ネイティブクライアント証明はその技術的な裏付けになっている。
frustration regex — 正規表現でユーザーの怒りを拾う
リークの中でSNSが最も盛り上がったのがこれだ。userPromptKeywords.tsに書かれていたユーザーの不満検知用の正規表現。
/\b(wtf|wth|ffs|omfg|shit(ty|tiest)?|dumbass|horrible|awful|
piss(ed|ing)? off|piece of (shit|crap|junk)|what the (fuck|hell)|
fucking? (broken|useless|terrible|awful|horrible)|fuck you|
screw (this|you)|so frustrating|this sucks|damn it)\b/LLMの会社が感情分析を正規表現でやっている。皮肉に見えるが、合理的だ。ユーザーが怒っているかの判定にLLM推論を回すのはコストも遅延も過剰すぎる。正規表現ならマイクロ秒で済む。応答トーンの調整トリガーとしてはこれで十分だろう。
業界への影響 — コードよりロードマップの流出が痛い
戦略的サプライズの喪失
512,000行のコード自体は、時間をかければ再構築できる。だがKAIROSやUndercover Modeのような未発表機能と戦略的方向性 は、一度知られたら巻き戻せない。OpenAI、Google、CursorはAnthropicの次の手を見たうえで自社の製品計画を練れるようになった。コードの流出は一時的だが、ロードマップの流出は長く効く。
npmエコシステムのソースマップ問題
ソースマップの誤配布はClaude Codeだけで起きた話ではない。ReactやAngularの本番バンドルに混入した例も散発的にある。たとえば2021年、保守系SNS GETTRではソースマップ経由でハードコードされた認証情報が見つかった。Bunのバンドラーがデフォルトでソースマップを生成する仕様は、npmエコシステム全体のビルド設定のもろさを浮き彫りにしている。
AI生成コードの透明性の議論
Undercover Modeの発覚は、AIが書いたコードをラベルなしでオープンソースに混ぜることの是非を突きつけた。EUのAI Actは高リスクAIシステムに透明性を求め、GitHubのContributor Covenantも意図的な不正表示を問題視している。AIが書いたコードを人間の手柄に見せる機能を、開発者コミュニティがどう受け止めるか。
開発者向け再発防止チェックリスト
Anthropic規模の企業でもソースマップ流出は起きる。npmパッケージを公開するなら、以下の3点は押さえておきたい。
.npmignoreに*.mapを追記するpackage.jsonのfilesフィールドを指定する.npmignoreのブラックリスト方式より確実だCI/CDにパッケージ内容チェックを入れる — npm pack --dry-runでパッケージの中身を公開前に確認するステップをパイプラインに追加する
どれも数分で設定できる。
まとめ
項目 詳細 発生日 2026年3月31日 直接原因 .npmignoreのソースマップ除外設定漏れ(ヒューマンエラー)背景因子 Bun Issue #28001(production modeでもソースマップ生成) 流出規模 512,000行 / 1,900ファイル / 59.8MB 影響 顧客データ・認証情報の漏洩なし 未公開機能 KAIROS(自律デーモン)、Undercover Mode、BUDDY、ULTRAPLAN GitHub フォーク ピーク時41,500以上(DMCA対象: 8,100リポジトリ) Anthropicの対応 ヒューマンエラーと認め、パッケージ差し替え+DMCA通知
Claude Mythos下書き公開に続く2件目のインシデントで、Anthropicのリリース工程の甘さが露わになった。流出したのはCLIツールの実装であり、AIモデルの重みやトレーニングデータではない。だが未発表のロードマップと内部戦略が競合に筒抜けになったことは、技術面よりビジネス面で響くだろう。
一方で、流出コードはAIコーディングツールの内部設計を覗ける数少ない実例にもなった。プラグイン型ツール構造、メモリ蒸留、Anti-Distillation。これらの設計パターンは今後のAIツール開発で広く参照されるはずだ。
よくある質問(FAQ)
Q. Claude Code流出で自分のデータが漏れた可能性はある?
A. Anthropicは顧客データや認証情報は含まれていないと明言している。漏れたのはCLIツールのソースコードで、ユーザーのコードやAPIキーは入っていない。ただしClaude Codeの内部動作が明るみに出たことで、プロンプトインジェクション攻撃の精度が上がるリスクは残る。
Q. ソースマップとは?
A. .mapファイルのこと。ビルド・圧縮後のJavaScriptから元のTypeScriptなどのソースを復元するための対応表だ。開発時のデバッグ用で、本番環境やパッケージに含めるものではない。
Q. KAIROSはいつリリースされる?
A. 公式発表はない。流出コードにフィーチャーフラグとして存在が確認されただけで、開発段階も完成度も分からない。流出を受けて計画自体が変わる可能性もある。
Q. Undercover Modeは倫理的に問題ないのか?
A. 見方が割れている。Anthropicの意図は社内ツールの痕跡を外部リポジトリに残さないことであり、悪意のある隠蔽とは限らない。ただしAI生成コードの開示を求める声が強まるなか、AIが書いたことを隠す機能の存在が批判されているのは事実だ。
Q. 同様のソースマップ流出を防ぐには?
A. 上の再発防止チェックリストの3点が基本になる。.npmignoreへの*.map追記、package.jsonのfilesフィールド指定、CI/CDでのnpm pack --dry-runチェックだ。
関連記事:
出典: