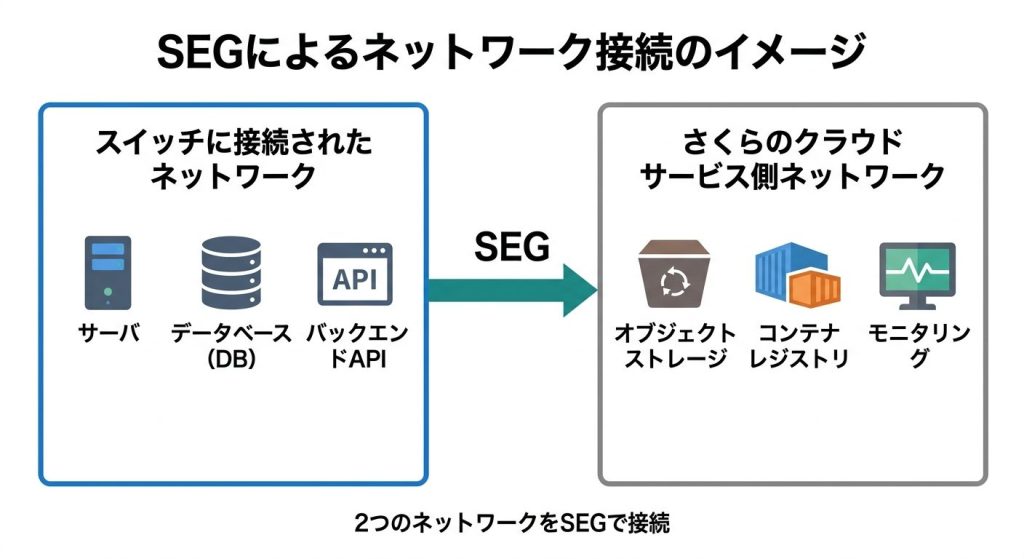
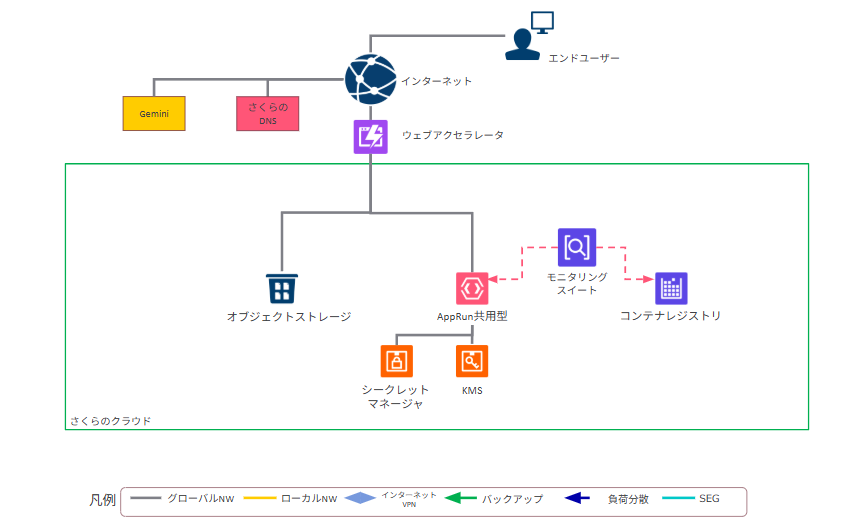
さくらインターネットが提供する「さくらのクラウド」が、ガバメントクラウドの対象クラウドサービスとして正式に採択されました。
デジタル庁は2026年3月27日、さくらのクラウドについて、すべての技術要件を満たしたことを確認し、同日以降、本番環境の提供が可能になったと公表しています。 また、さくらインターネットも、305項目すべての技術要件への適合が確認され、令和5年度および令和8年度のガバメントクラウドサービス提供事業者として採択されたことを発表しています。
これは、国産クラウドの選択肢が公共領域でも現実的に広がったという意味で、大きなニュースです。
一方で、ITエンジニアやSIerの現場では、次のような現実的な不安も出ています。
さくらのクラウドを、現場で誰が設計し、誰が構築し、誰が運用するのか。
クラウドサービスが正式採択されたことと、そのクラウドを安全に導入・運用できることは、同じではありません。
これから重要になるのは、さくらのクラウドを理解し、要件に合わせて設計・構築・運用できるパートナーの存在です。
💡この記事はこんな方におすすめです
- さくらのクラウドの導入を検討している企業・自治体関係者
- ガバメントクラウド採択後の現場課題を知りたい方
- 国産クラウドを活用したシステム基盤を検討している方
- さくらのクラウドに対応できる導入・運用パートナーを探している方
- AWS・Azure以外のクラウド選択肢を検討したい方
この記事でわかること
- ✅ さくらのクラウドが注目されている背景
- ✅ ガバメントクラウド採択後に現場で問われるポイント
- ✅ 運用管理補助者・MSP不足がなぜ課題になるのか
- ✅ 305項目の技術要件を現場でどう扱うべきか
- ✅ さくらのクラウド導入でパートナー選びが重要になる理由
国産クラウドの選択肢が、いよいよ現実的になってきた
これまでガバメントクラウドというと、AWS、Google Cloud、Microsoft Azure、Oracle Cloud Infrastructureなど、外資系クラウドを中心に議論されることが多くありました。
その中で、さくらのクラウドがガバメントクラウドの対象クラウドサービスとして正式採択されたことは、国産クラウドの選択肢が公共領域でも現実的に広がったという意味で、大きな転換点です。
特に、行政・自治体・公共性の高いシステムでは、データの保管場所、運用主体、国内法との整合性、サポート体制などが重要になります。
そのため、国内事業者が提供するクラウドを選択肢に入れられることは、多くの企業・自治体にとって大きな意味があります。
一方で、クラウドサービスが正式採択されたからといって、すぐに現場で問題なく使えるわけではありません。
実際の導入では、要件整理、構成設計、ネットワーク設計、セキュリティ設計、監視・バックアップ設計、運用体制づくりまで含めて検討する必要があります。
なぜ今、「さくらのクラウドを扱えるパートナー」が注目されているのか
さくらのクラウドがガバメントクラウドの対象クラウドサービスとして正式採択されたことで、国産クラウド活用への期待は大きく高まりました。
一方で、現場では次のような流れで、実務面の課題が見え始めています。
-
正式採択への期待
国産クラウドがガバメントクラウドの選択肢として現実的になった。 -
現場からの冷静な問い
では、実際に誰が設計し、設定し、運用するのか。 -
パートナー不足への懸念
さくらのクラウドに対応できるSIer・MSP・運用パートナーが十分にいるのか。 -
導入支援ニーズの高まり
構成検討、見積、移行、運用設計まで支援できるパートナーの重要性が増している。
つまり、今後は「さくらのクラウドが使えるかどうか」ではなく、 「さくらのクラウドを使って、安全にシステムを構築・運用できる体制を作れるか」が問われる段階に入っています。
現場で問われている3つの課題
1. 運用管理補助者・MSP(マネージドサービスプロバイダー)不足への不安
ガバメントクラウドを自治体が利用する場合、クラウド環境やクラウドサービスの運用管理を補助する「ガバメントクラウド運用管理補助者」の役割が重要になります。
これは一般的にいうと、クラウドの設計・設定・運用を支援する MSP(マネージドサービスプロバイダー) に近い役割です。
MSPとは、クラウドやサーバ、ネットワークなどのIT基盤について、構築後の監視・運用・保守・障害対応などを継続的に支援する事業者を指します。
ただし、ガバメントクラウドにおける「運用管理補助者」は、一般的なMSPと完全に同じ意味ではありません。 地方公共団体のクラウド利用を支える立場として、責任分界や運用範囲を明確にしたうえで関わる必要があります。
現場で不安視されているのは、AWSやAzureに対応できる事業者は多くても、さくらのクラウドの仕様や設計思想を理解し、公共領域の要件に合わせて構築・運用できる事業者がまだ限られているのではないか、という点です。
現場で想定される懸念
- 自治体が「さくらのクラウドを使いたい」と考えても、既存の委託先が対応できない
- 付き合いのあるSIerから「AWSやAzureなら対応できるが、さくらは難しい」と言われる
- 構成設計・見積・運用体制を具体化できず、クラウド選定が進まない
- 結果として、使いたくても使えない「ベンダーブロック」が発生する
このような状況を避けるためには、早い段階でさくらのクラウドに対応できる導入・運用パートナーへ相談し、構成案・費用感・運用体制を整理しておくことが重要です。
2. 305項目の技術要件を、誰が現場で運用するのか
さくらのクラウドは、デジタル庁により305項目すべての技術要件への適合が確認され、ガバメントクラウドの対象クラウドサービスとして正式採択されました。
これは非常に大きな実績です。 一方で、クラウドサービス提供事業者が技術要件を満たしたことと、利用者側のシステムが安全に設計・運用されることは、同じではありません。
実際の現場では、以下のような設計・運用判断が必要になります。
- どのサービスをどの構成で使うべきか
- 外部公開領域と内部管理領域をどう分離するか
- 権限管理やアクセス制御をどう設計するか
- ログ・監視・バックアップをどこまで実装するか
- 障害発生時の一次対応を誰が行うか
- 月次報告や監査対応に必要な情報をどう残すか
つまり、305項目の技術要件を満たしたクラウドを使うには、その上で構築するシステム側にも、相応の設計力・運用力が求められます。
重要なのは、「さくらのクラウドが要件を満たしているか」だけではありません。
そのクラウドを使って、要件に合った安全な構成を組めるかどうかです。
3. AWS・Azure人材とのスキルセットの壁
もう一つの論点は、エンジニアのスキルセットです。
現在のクラウド人材市場では、AWS、Azure、Google Cloudなどの経験を持つエンジニアは比較的見つけやすい一方で、さくらのクラウドを実務レベルで扱えるエンジニアやSIerは、まだ限られていると考えられます。
そのため、さくらのクラウドを選択肢に入れる場合は、単に「クラウド経験者がいるか」ではなく、以下の観点で確認することが重要です。
- さくらのクラウドのサービス体系を理解しているか
- サーバ、スイッチ、ルータ、VPN、DB、ストレージの構成を設計できるか
- さくらのクラウド特有の料金体系や制約を踏まえて見積もれるか
- 監視・バックアップ・ログ・障害対応まで運用設計できるか
- AWSやAzureとの違いを説明し、適切に比較できるか
クラウドの選定では、製品そのものの機能だけでなく、導入を支える人材・パートナーの有無が成否を左右します。
さくらのクラウド導入でつまずきやすいポイント
1. AWSやAzureと同じ感覚で設計してしまう
クラウドの基本的な考え方は共通していますが、サービス体系やネットワーク構成、料金体系、監視方法、運用の考え方はクラウドごとに異なります。
AWSやAzureの知識があることは大きな強みですが、そのままさくらのクラウドに置き換えればよいとは限りません。 さくらのクラウドのサービス特性を理解したうえで、構成を組み立てる必要があります。
2. ネットワークとセキュリティの設計が後回しになる
さくらのクラウドでは、サーバ、スイッチ、ルータ+スイッチ、VPNルータ、ロードバランサ、オブジェクトストレージ、AppRun、DBアプライアンスなど、さまざまなサービスを組み合わせて構成を検討します。
特に重要なのは、外部公開する領域と内部管理する領域をどう分けるかです。 インターネット公開、VPN接続、閉域接続、管理用ネットワーク、WAF、監視、ログ取得などを、要件に合わせて整理する必要があります。
3. 構築だけで終わり、運用設計が不足する
クラウド導入でよくある失敗は、構築まではできたものの、運用体制が整っていないケースです。
たとえば、以下のような点が曖昧なままだと、運用開始後に問題が起きやすくなります。
- 障害発生時に誰が一次確認するのか
- リソース使用率をどの頻度で確認するのか
- ログをどこまで確認するのか
- バックアップ取得状況をどう確認するのか
- 証明書や契約更新を誰が管理するのか
- 月次報告として何を提出するのか
安心して運用するためには、構築段階から保守・運用・報告までを見据えておくことが重要です。
弊社は、さくらのクラウドのパートナーとして導入を支援しています
弊社は、さくらのクラウドのパートナーとして、クラウド導入・構成検討・運用支援に取り組んでいます。
さくらのクラウドの導入では、単にサーバを作成するだけではなく、要件に応じてネットワーク、セキュリティ、監視、バックアップ、運用体制まで含めて設計する必要があります。
弊社では、さくらのクラウドを活用したシステム基盤について、導入前の相談から構成検討、見積、運用設計まで支援しています。
弊社が支援できること
- ✅ さくらのクラウドを前提とした構成設計
- ✅ 既存システムからの移行方針整理
- ✅ ネットワーク・セキュリティ設計
- ✅ AppRun、DBアプライアンス、オブジェクトストレージ等の活用検討
- ✅ 監視・ログ・バックアップ方針の整理
- ✅ 月次報告や運用体制の設計
- ✅ AWS・Azure等との比較を踏まえたクラウド選定支援
- ✅ 公共・自治体領域を見据えた要件整理
弊社の強みは、単にクラウドリソースを用意するだけではありません。
「どの構成なら安全に運用できるか」
「どこまでをマネージドサービスに任せるべきか」
「どこから運用設計が必要になるか」
「月次報告や保守体制として何を整えるべきか」
こうした現場目線の論点まで含めて、さくらのクラウド活用を支援できる点が弊社の特徴です。
このようなご相談に対応できます
- さくらのクラウドでシステムを構築できるか知りたい
- 公共・自治体向けの提案で、さくらのクラウドを選択肢に入れたい
- AWS・Azureとさくらのクラウドを比較したい
- 国産クラウドを活用した構成案を作りたい
- さくらのクラウドの月額費用を見積もりたい
- 既存システムをさくらのクラウドへ移行できるか確認したい
- ネットワークやセキュリティ構成に不安がある
- 構築後の保守・運用・月次報告まで相談したい
さくらのクラウド導入では、早い段階でパートナーに相談することが重要
さくらのクラウドは、今後さらに注目されるクラウドになると考えられます。
一方で、クラウド導入は「どのサービスを使うか」だけで成功するものではありません。 要件に合わせた構成を設計し、セキュリティ・運用・コストまで含めて検討する必要があります。
特に、公共・自治体・準公共領域のシステムでは、要件整理の段階からクラウド構成を意識しておくことが重要です。 あとからネットワークや運用を追加しようとすると、構成変更や見積もりのやり直しが発生しやすくなります。
そのため、さくらのクラウドの活用を検討している場合は、できるだけ早い段階で導入・運用パートナーに相談することをおすすめします。
まとめ:さくらのクラウド活用は「導入できるパートナー選び」が重要になる
さくらのクラウドがガバメントクラウドの対象クラウドサービスとして正式採択されたことにより、国産クラウド活用の可能性は大きく広がりました。
一方で、これからの現場では、次の問いがより重要になります。
さくらのクラウドを、安全に設計・構築・運用できるパートナーはいるのか。
弊社は、さくらのクラウドのパートナーとして、導入前の相談から、構成設計、見積もり、運用設計まで支援しています。
さくらのクラウドの活用を検討されている方は、ぜひお気軽にご相談ください。
さくらのクラウド導入をご検討中の方へ
弊社では、さくらのクラウドの構成検討・見積もり・導入支援・運用設計をサポートしています。
「さくらのクラウドで実現できるか知りたい」
「AWSやAzureとの違いを比較したい」
「公共系システムで使える構成を相談したい」
といった段階からご相談可能です。
さくらのクラウドの導入・移行・運用についてお悩みの方は、まずはお気軽にお問い合わせください。
参考情報
※本記事は、公開情報をもとに、さくらのクラウド導入・運用における実務上の論点を整理したものです。 ガバメントクラウドに関する個別要件や対応可否については、案件ごとに確認が必要です。